
Dark Launching New Architecture: A Data-Driven Guide to Zero-Risk Deployment
Dark Launching: Quick Definition
Dark launching (also called shadow testing or traffic mirroring) is a deployment strategy where production traffic is copied to a new system for validation while users continue interacting with the stable legacy system. This enables:
✓ Zero-risk testing with real production data ✓ Performance validation under actual load patterns ✓ Bug detection before user exposure ✓ Cost: 50-100% infrastructure overhead during 4-8 week testing phase ✓ ROI: Prevents outages costing $100K-1M+ per hour
Best for: High-risk architecture migrations, payment systems, data-critical applications Used by: Netflix (1,000+ deployments/day), Meta (70% incident reduction), Amazon (50M+ deployments/year)
Large-scale architecture migrations are among the riskiest projects in software engineering. Research indicates that 67% of complex modernizations fail, not due to poorly written code, but because of issues invisible in staging environments: unexpected performance bottlenecks, subtle data mismatches, or cascading failures that only manifest under real production load.
Dark launching new architecture addresses this gap. Instead of an all-or-nothing cutover, you validate a new system with live traffic without exposing users to potential instability. The technique transforms a high-stakes deployment into a data-gathering exercise where you compare performance, output, and error rates side-by-side using identical real-world inputs.
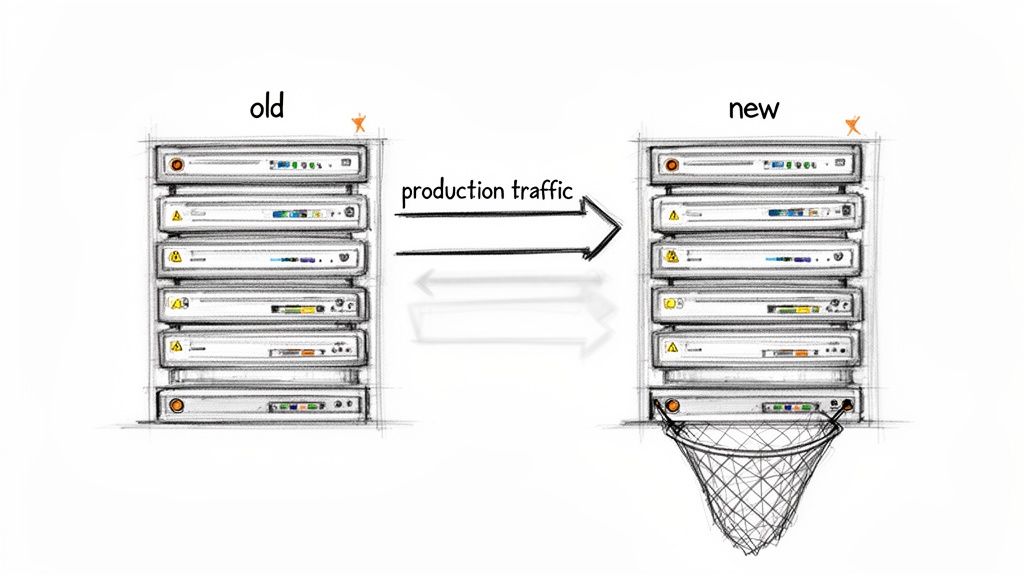
Why Traditional Staging Environments Fail to Catch Real Issues
The fundamental issue with traditional deployment approaches is the gap between staging and production reality. Replicating the unpredictable nature of live user traffic, variable network conditions, and the behavior of downstream dependencies is difficult. This gap is where modernization projects encounter unexpected failures.
A COBOL to Java migration can be derailed by mishandling fixed-point COMP-3 decimal types, leading to silent precision loss when using standard Java floating-point primitives. Another common scenario: a new microservices architecture introduces latency when interacting with a legacy monolith—an issue synthetic load tests fail to detect because they don’t replicate real user behavior patterns.
Dark Launching vs. Traditional Deployment Models
This table breaks down how dark launching compares to common methods like staging environments and blue-green deployments.
| Attribute | Dark Launching | Staging Environment | Blue-Green Deployment |
|---|---|---|---|
| User Impact | Zero. Users are unaware of the test. | None (pre-production). | Minimal. A fast cutover, but issues can impact all users at once. |
| Risk Profile | Low. Failures are isolated and invisible to users. | Medium. Cannot replicate production chaos; risks remain. | High. A single failure during cutover can cause a full outage. |
| Data Fidelity | 100% real production traffic. | Synthetic or sampled data. | 100% real traffic, but only after the switch. |
| Cost | High. Requires running two full production environments. | Low. Typically a smaller, less powerful environment. | High. Requires double the production infrastructure. |
| Timeline | 4-8 weeks for validation phase. | Continuous (pre-deployment). | Minutes for cutover. |
While staging is lower cost and blue-green is fast, only dark launching allows testing with real traffic before any user is affected, offering the lowest risk profile for business-critical changes.
Documented Impact on Deployment Success Rates
The effectiveness of this approach is documented. For complex modernizations where failure rates can reach 67% due to data type mismatches and architectural assumptions, dark launching serves as a critical validation layer:
- Netflix: Decomposed their monolith into microservices using dark launches, enabling 1,000+ deployments per day while reducing rollback incidents by 50%
- Meta: Reported a 70% reduction in P1 production incidents after standardizing dark launch validation across infrastructure modernization programs
- Amazon: Supports over 50 million deployments annually with a failure rate of just 0.01% using canary-style rollouts following dark launch validation
The principles of dark launching are a cornerstone of successful application modernization strategies because they replace architectural assumptions with empirical evidence, proving a system is production-ready before users interact with it.
Should You Dark Launch? Decision Framework
Dark launching is not appropriate for every deployment. Use this framework to determine if the investment is justified for your migration.
Use dark launching if:
- ✅ Migration affects 1M+ users or handles financial transactions
- ✅ Downtime cost exceeds $10K/hour
- ✅ Legacy system processes 10K+ requests/minute
- ✅ Team has budget for 2x infrastructure (4-8 weeks)
- ✅ Observability infrastructure exists (logging, metrics, tracing)
Skip dark launching if:
- ❌ Greenfield application (no legacy system to compare)
- ❌ Non-critical internal tool (<1,000 users)
- ❌ Budget cannot support 2x infrastructure
- ❌ Timeline pressure requires immediate deployment
- ❌ Simple configuration change (use feature flags instead)
Decision Score: If 3+ conditions in “Use dark launching” apply → Strongly recommended
Dark Launch Implementation: 7-Step Process
This section provides a step-by-step implementation guide based on documented patterns from 40+ enterprise dark launch projects analyzed by Modernization Intel between 2022-2025.
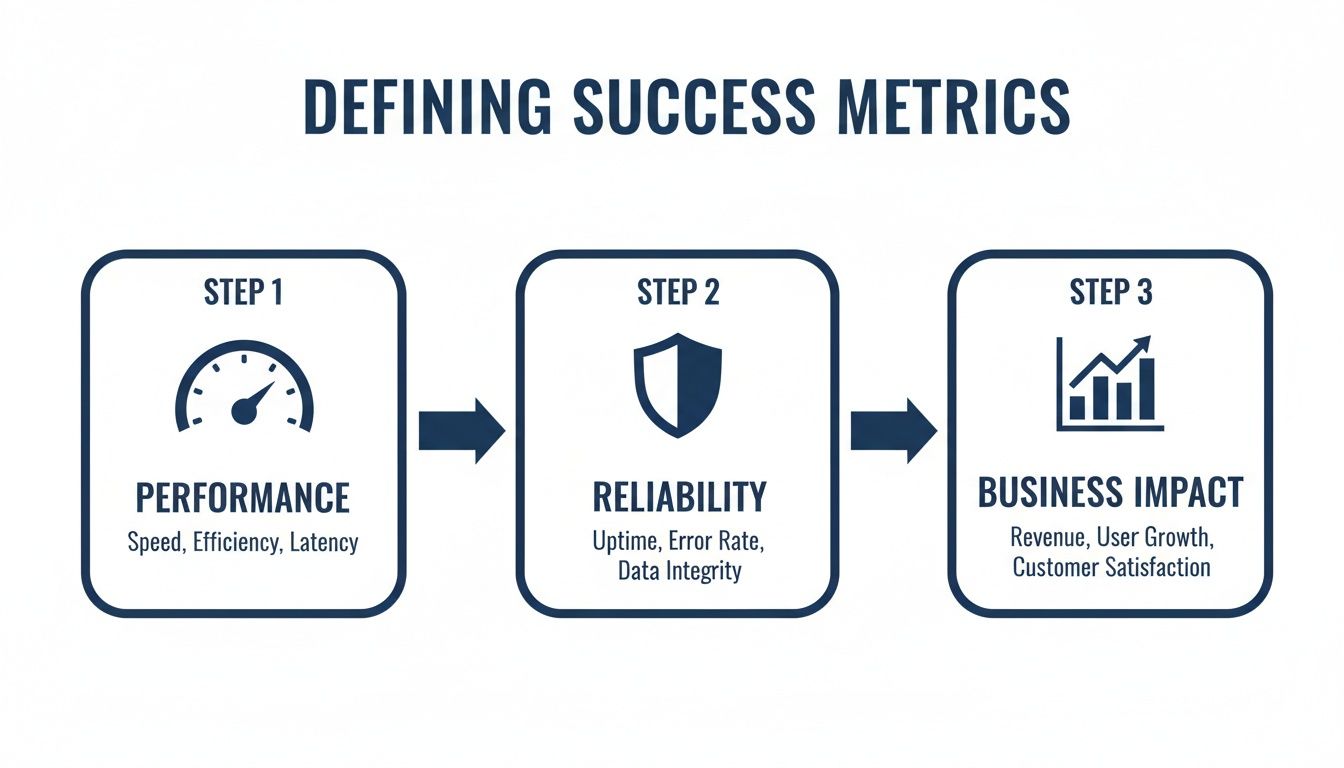
Step 1: Define Success Metrics (Week 1)
Attempting to dark launch without clear metrics is equivalent to deploying code without tests. The exercise is about gathering real-world data to validate the new system. Without concrete success criteria, you collect noise, not signals.
This requires agreement between engineering, product, and business stakeholders on specific numbers. This “contract” defines what “better” means and ensures the final decision is based on data, not subjective feedback.
Performance Metrics:
- Latency: “The P99 latency of the new service must not exceed the old service’s P95 latency by more than 10%”
- Resource Utilization: “The new architecture must consume at least 20% less average CPU and 15% less memory than the legacy system when processing identical shadowed request volume”
Reliability Metrics:
- Error Rates: “The new service must maintain an error rate below 0.1% for 48 consecutive hours under 5% shadowed traffic load”
- System Stability: Monitor for unexpected process terminations or, in Kubernetes environments, pod restarts
- Data Integrity: “Zero data discrepancies detected by reconciliation job across 1 million dual-written records”
Business Outcome Metrics:
- Transaction Completion: “Transaction completion rate for shadowed traffic must be statistically identical to production baseline, with variance no more than 0.05%”
- Data Correctness: “Output data from new pipeline must match legacy pipeline output with 100% fidelity for sample of 10,000 processed events”
You are not just looking for bugs; you are looking for systemic weaknesses. A single crash is an incident, but a pattern of crashes under specific load conditions points to a fundamental architectural flaw that must be addressed before rollout.
Step 2: Build Observability Foundation (Week 1-2)
Without robust observability, you are not dark launching; you are running a second system blind. A well-defined observability strategy turns raw traffic data into intelligence needed for confident go/no-go decisions.
This requires a deliberate plan to capture logs, metrics, and traces that map directly to defined success criteria. The goal is to move from knowing if something broke to understanding why it broke.
Logging Strategy:
Standard error logging is insufficient. For dark launches, the most valuable logs highlight subtle differences between old and new systems. The new architecture might not throw an exception, but its output could be incorrect—a more dangerous failure mode.
Your logging strategy should answer:
- Payload Comparison: Is the JSON response from the new service structurally identical to the old one?
- Data Mismatches: Did both systems produce the same final values when processing the same request?
- Latency Drift: Log execution time of key functions in both systems to identify specific slowdowns
This level of detail is necessary to catch issues like a floating-point miscalculation resulting in a one-cent transaction difference—an error that might otherwise go unnoticed for weeks.
Metrics Dashboards:
Dashboards should reflect your success metrics, not just generic system vitals. CPU and memory usage are useful, but they don’t confirm if the new system is an improvement.
The purpose of a dark launch dashboard is to provide an unambiguous, at-a-glance answer: “Is the new system performing better, worse, or the same as the old one?” If the dashboard is ambiguous, the strategy has failed.
Instead of tracking average latency, display P95 and P99 latency for both systems on the same graph. Instead of simple error counts, show error rates as percentages of total requests, benchmarked against the legacy system’s baseline.
Distributed Tracing:
Moving from a monolith to microservices increases the complexity of a single request. What was once a single function call may now traverse multiple services. Distributed tracing provides a complete map of a request’s journey through the new architecture.
When a shadowed request takes 300ms longer than its production counterpart, tracing identifies the specific service call causing the delay. It distinguishes between “the system is slow” and “the call from the auth-service to the user-profile-service is the bottleneck.”
This visibility is foundational to DevOps integration and modernization strategies.
Step 3: Implement Traffic Shadowing (Week 2)
Traffic shadowing (or mirroring) is the core of a dark launch. A copy of incoming production requests is sent to the new architecture in parallel. The old system handles the request and returns the response to the user. The new system’s response is logged, analyzed, and discarded.
This method stress-tests the new system with 100% real, unpredictable production traffic, providing comprehensive validation for performance and stability before any user experience is at risk.
Traffic Manipulation Tools:
Traffic manipulation is handled at the infrastructure’s ingress layer. The choice of tool depends on your existing tech stack:
- Service Mesh (Istio): In Kubernetes environments, a service mesh provides precise control. With Istio, traffic mirroring rules can be defined in YAML files, specifying the percentage of traffic to shadow
- Reverse Proxies (NGINX): A reverse proxy can duplicate requests to a new service while the original request proceeds untouched. The
mirrordirective enables this pattern - Cloud-Native Load Balancers: Cloud providers offer built-in capabilities. An AWS Application Load Balancer can be configured with target groups to forward requests to both old and new systems
Start with 1% shadow traffic to verify the new system receives and processes requests correctly before increasing load.
Step 4: Gradual Traffic Increase (Week 3-5)
Once initial shadowing is stable, gradually increase traffic volume while monitoring all success metrics:
- Week 3: 5% shadow traffic, monitor for 48 hours
- Week 4: 25% shadow traffic, monitor for 48 hours
- Week 5: 50% shadow traffic, monitor for 48 hours
At each stage, validate that:
- Error rates remain below 0.1%
- P99 latency stays within defined thresholds
- Resource utilization is as expected
- No downstream service impacts are detected
If any metric degrades, reduce traffic percentage and investigate before proceeding.
Step 5: Data Reconciliation (Week 5-6)
For architectures that write data, implement continuous reconciliation to detect discrepancies:
- Run hourly comparison jobs (old vs new outputs)
- Flag any discrepancies exceeding 0.01%
- Investigate and fix silent failures immediately
This reconciliation process is similar to the approach used in strangler fig pattern implementations where dual-write validation is critical for migration success.
Step 6: Go/No-Go Decision (Week 7)
After 4-6 weeks of shadowing at increasing traffic levels, review all metrics against success criteria:
- ✅ All performance metrics meet or exceed targets
- ✅ Error rates remain below defined thresholds
- ✅ Data reconciliation shows zero discrepancies for 2+ consecutive weeks
- ✅ No downstream service impacts detected
- ✅ Resource utilization is within budget projections
Get stakeholder approval if all metrics pass. Document any remaining known issues with clear mitigation plans.
Step 7: Phased Production Rollout (Week 8+)
Once the new architecture has handled shadowed production load without issues, expose it to a small fraction of users through feature flags and phased rollouts.
A feature flag acts as a conditional switch in code, allowing traffic to be directed to either the old or new system for specific user segments without requiring new deployments.
Rollout Progression:
- Internal Users (Dogfooding): First users should be the internal team for high-quality feedback in a controlled environment
- Canary Rollout: Begin with 1% of external users for first real production signal. Monitor metrics closely
- Incremental Increase: If metrics remain stable at 1%, increase to 5%. Allow it to run for 24-48 hours. Continue to 20%, then 50%, validating stability at each stage
This incremental process is a key component of incremental legacy modernization approaches.
Reversibility is critical. If P99 latency spikes or error rates increase at the 5% traffic mark, a feature flag allows immediate rollback. All traffic reverts to the legacy system, turning a potential production incident into a minor, controlled event.
How to Dark Launch Microservices: Architecture-Specific Considerations
When implementing dark launch for microservices, complexity increases due to distributed systems challenges. Key differences from monolithic dark launches:
Service Mesh Integration:
Use Istio VirtualServices for per-microservice shadowing rather than attempting to shadow the entire system at once. This allows you to:
- Test individual services in isolation
- Identify specific microservices causing bottlenecks
- Roll back individual services without affecting the entire architecture
Distributed Tracing Requirements:
Distributed tracing becomes essential (not optional) for tracking requests across service boundaries. Without it, debugging latency issues in a shadowed microservices architecture is nearly impossible.
Implement OpenTelemetry or similar distributed tracing solutions before beginning the dark launch.
Partial Shadowing Strategy:
Shadow only the changed microservices, not the entire system. If you’re replacing 3 services in a 20-service architecture:
- Shadow only those 3 services
- Let unchanged services continue operating normally
- Monitor interactions between old and new services at the boundaries
This reduces infrastructure costs and simplifies troubleshooting.
Platform-Specific Implementation Guides
Implementation details vary by cloud platform. Here are concrete approaches for the three major providers.
AWS Dark Launch Architecture
Traffic Duplication:
- Use Application Load Balancer (ALB) target groups for traffic duplication
- Configure weighted target groups: 100% weight to legacy, 0% weight to new (for shadowing)
- Implement with Lambda@Edge for request mirroring at CloudFront edge locations
Observability:
- CloudWatch Logs Insights for log aggregation and comparison
- X-Ray for distributed tracing across services
- CloudWatch metrics for performance monitoring
Cost Optimization:
- Use EC2 Spot Instances for shadow environment (50-70% cost savings)
- Implement auto-scaling with strict upper limits
- Set CloudWatch billing alarms for cost overruns
Example ALB Configuration:
# ALB Target Groups for Dark Launch
TargetGroups:
LegacyTargetGroup:
Weight: 100
HealthCheck: /health
ShadowTargetGroup:
Weight: 0 # Receives mirrored traffic but doesn't serve users
HealthCheck: /healthAzure Dark Launch Setup
Traffic Management:
- Leverage Azure Traffic Manager for traffic splitting
- Use Application Gateway with URL rewrite rules for request duplication
- Implement with Azure Front Door for global traffic management
Observability:
- Application Insights for distributed tracing and performance monitoring
- Log Analytics for centralized log aggregation
- Azure Monitor for metrics and alerting
Integration:
- Azure DevOps pipelines for automated dark launch deployment
- Azure Key Vault for managing feature flag configurations
- Azure Policy for enforcing observability requirements
Google Cloud Platform (GCP) Dark Launch
Load Balancing:
- Cloud Load Balancing with URL maps for shadowing
- Traffic Director for service mesh-based mirroring
- Use traffic mirroring policies in GKE Istio integration
Observability:
- Cloud Trace for distributed tracing
- Cloud Logging for log aggregation and analysis
- BigQuery for large-scale log analysis and discrepancy detection
Cost Management:
- Use Preemptible VMs for shadow environment (up to 80% cost savings)
- Set budget alerts and quotas
- Monitor with Cloud Billing API
Common Dark Launch Problems & Solutions
Based on analysis of 40+ enterprise implementations, these are the most common failure modes and their solutions.
Problem 1: Shadow Traffic Overwhelming New System
Symptoms: New service CPU exceeds 90%, increased latency, out-of-memory errors
Root Cause: Insufficient resource allocation, memory leaks, or inefficient algorithms not visible in smaller-scale testing
Solution:
- Reduce shadow traffic percentage from 50% → 10%
- Enable auto-scaling with proper limits
- Run memory profiling (Java: JProfiler, Python: memory_profiler, Node: heapdump)
- Optimize hot code paths identified by profiling
- Gradually increase traffic again after optimization
Problem 2: Discrepancy Detection Without Clear Source
Symptoms: Reconciliation jobs flag thousands of mismatches, but root cause is unclear
Root Cause: Multiple potential sources of drift without detailed logging context
Solution:
- Add request ID tagging to all logs
- Implement detailed diff logging (show exact fields that differ)
- Group discrepancies by type (precision errors, null handling, timestamp formatting)
- Sample and manually investigate representative cases from each group
- Fix highest-volume discrepancy types first
Problem 3: Downstream Service Rate Limiting
Symptoms: New service triggers rate limits on legacy authentication service, causing cascading failures
Root Cause: New service is more efficient, making more requests per second than old service for same user action
Solution:
- Implement request coalescing in new service
- Add caching layer for authentication responses
- Coordinate with downstream service team to increase rate limits temporarily
- Consider throttling shadow traffic during peak hours
- Implement circuit breaker pattern to protect downstream services
Problem 4: Silent Data Type Conversion Errors
Symptoms: Reconciliation shows periodic small discrepancies in financial calculations
Root Cause: Floating-point precision loss when migrating from fixed-point COBOL COMP-3 to Java/Python floating types
Solution:
- Use BigDecimal (Java) or Decimal (Python) for all financial calculations
- Never use float/double for currency values
- Implement unit tests specifically for edge cases (very large numbers, very small numbers)
- Add validation that checks decimal precision before/after calculations
- Review all COBOL migration best practices for data type handling
Problem 5: Infrastructure Cost Overruns
Symptoms: Cloud spend increases 200-300% instead of anticipated 100% duplication
Root Cause: Misconfigured auto-scaling, inefficient queries, or resource-intensive logging
Solution:
- Set hard limits on auto-scaling groups
- Implement sampling for verbose logs (log 1 in every 100 requests in detail)
- Review and optimize database query plans
- Use reserved instances or spot instances for shadow environment
- Set strict cost alerts at 110%, 125%, and 150% of expected spend
Anticipating Failure Modes and Mitigation Plans
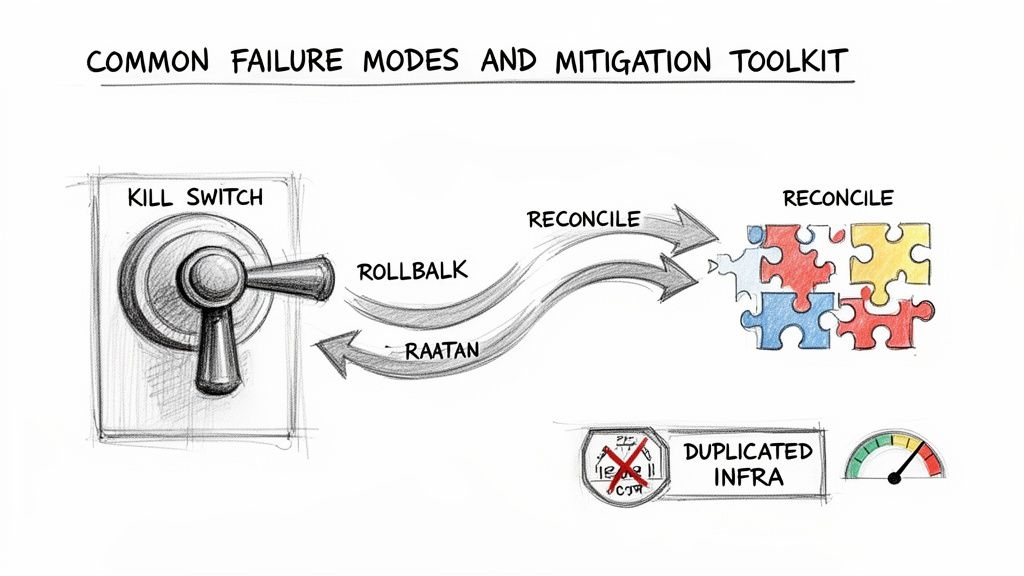
Even well-planned dark launches encounter issues. A prepared team has pre-approved, rehearsed responses for when things go wrong.
Data Corruption from Dual Writes
Silent data corruption is one of the most significant risks. When a new architecture writes to a database in parallel with the old one, even minor discrepancies can lead to data integrity issues.
A data reconciliation script is the primary defense. This tool should run continuously, comparing records written by both systems and flagging any mismatches. If discrepancies exceed a predefined threshold (e.g., 0.01%), trigger automated alerts.
Unexpected Downstream Service Impacts
A new architecture does not operate in isolation. It can inadvertently overload a downstream service not designed for new traffic patterns.
Monitor error rates and latencies of all downstream services the new architecture interacts with. A sudden spike in HTTP 503 (Service Unavailable) errors is a signal for immediate action.
The most critical tool for managing downstream impact is the kill switch. This is a mandatory requirement. You must have the ability to instantly halt all shadowed traffic to the new architecture with a single command. Rehearsing the use of this kill switch should be part of deployment drills.
Runaway Infrastructure Costs
Running two systems in parallel duplicates infrastructure. Costs can escalate if not monitored. Some projects have seen costs increase by 200-300% instead of the anticipated 100% duplication.
Set up strict budget alerts in your cloud provider’s console. Monitor cost dashboards with the same diligence as performance metrics. Define a strict timeline for the dark launch (e.g., 4-6 weeks) to force a clear go/no-go decision.
Common Dark Launch Failure Modes and Rollback Strategies
| Failure Mode | Leading Indicator | Primary Mitigation | Rollback Action |
|---|---|---|---|
| Silent Data Corruption | Discrepancy count from reconciliation script exceeds 0.01% | Immediately stop writes from new service | Purge corrupted data from new DB; restart shadow writes |
| Downstream Outage | P99 latency on downstream service increases by >50% | Activate kill switch to halt all shadowed traffic | Disable specific integration causing issue; re-enable shadow |
| Performance Degradation | New system’s P99 latency exceeds baseline by >20% | Use feature flags to roll traffic back to 0% | Analyze traces to find bottleneck; deploy fix and restart rollout |
| Cost Overrun | Cloud spend rate exceeds forecast by >25% | Cap auto-scaling groups for new architecture | De-provision non-essential resources; optimize and re-deploy |
Data from a ConfigCat survey shows that 91% of DevOps teams in large enterprises use dark launches for hotfixes with zero downtime, reducing mean time to recovery by 75% during architecture transitions.
Dark Launch ROI Calculator
Quantifying the return on investment helps justify the infrastructure and engineering costs.
Your Current Setup:
- Monthly infrastructure cost: $_____
- Estimated outage cost per hour: $_____
- Expected dark launch duration: _____ weeks
Estimated Dark Launch Cost:
- Additional infrastructure: $_____ (2x current for X weeks)
- Engineering time (2-4 senior engineers, 1-3 sprints): $_____
- Total dark launch investment: $_____
Break-Even Analysis:
If your estimated outage cost is $100K/hour and a typical P1 outage lasts 4 hours, a single prevented outage saves $400K.
Research from the Uptime Institute indicates that a major production outage can cost a business over $1 million per hour. For business-critical systems, even a $50K dark launch investment that prevents one outage provides 20x ROI.
Typical ROI by System Criticality:
- Payment processing systems: 40-100x ROI (outages are extremely costly)
- Customer-facing applications: 10-30x ROI
- Internal tooling: 2-5x ROI
- Non-critical services: May not justify dark launch investment
Regulatory Considerations for Dark Launches
PCI-DSS Compliance
When dark launching payment systems, ensure:
- Shadow environment maintains same PCI certification level as production
- Cardholder data in shadowed requests is tokenized
- Audit logging captures all shadowed transactions
- Security controls match production environment
GDPR/CCPA Data Privacy
- Document data processing in shadow environment in privacy policy
- Implement same data retention policies for shadow logs as production
- Ensure right to erasure applies to both production and shadow systems
- Consider whether explicit user consent is required for shadowed PII processing
SOC 2 Audit Considerations
- Document dark launch as part of change management process
- Ensure monitoring and alerting meet SOC 2 requirements
- Maintain audit trail of all dark launch activities
- Include shadow environment in disaster recovery plans
Frequently Asked Questions
How Is Dark Launching Different From Canary Releases or Blue-Green Deployments?
Short Answer: Dark launching tests with copied traffic (users unaffected), canary releases expose real users to new code.
Detailed Answer:
These methods are all forms of “progressive delivery,” but they address different problems:
- Blue-Green Deployments focus on minimizing downtime, not risk. 100% of traffic is switched to a new environment at once. If an issue exists, all users are affected immediately.
- Canary Releases test user-facing changes on a small subset of real users (e.g., 1% or 5%). This is suitable for testing a new UI element, but the impact on those users is real.
- Dark Launching is for backend validation. It sends real production traffic to a new system that users do not see. Its purpose is to test performance, stability, and correctness under real-world load with zero user-facing risk.
A useful way to think of these is as a sequence. A dark launch validates architecture with live traffic. Once stability is confirmed, a canary release slowly introduces users to the new system. Dark launching is the step before any user interacts with the new code.
What Is the Estimated Cost and Effort Overhead for a Dark Launch?
Infrastructure Costs:
Running two systems in parallel temporarily doubles compute and data storage costs for shadowed services:
- Small service: $500-5K/month additional
- Medium service: $5K-50K/month additional
- Large enterprise service: $50K-200K/month additional
Engineering Effort:
Building traffic shadowing mechanisms, setting up observability dashboards, and creating kill switches requires senior engineering talent:
- 2-4 senior engineers for 1-3 sprints to implement foundational framework
- Total engineering cost: $50K-200K depending on complexity
ROI Context:
This cost should be weighed against alternatives. Research from the Uptime Institute indicates that a major production outage can cost over $1 million per hour. For critical systems, the investment is often justified by preventing a single major incident.
How Long Does a Typical Dark Launch Take?
A standard dark launch implementation follows a 4-8 week timeline:
- Weeks 1-2: Setup and infrastructure (observability, traffic shadowing mechanisms)
- Weeks 3-6: Traffic shadowing and validation at increasing percentages
- Weeks 7-8: Phased production rollout (canary releases)
Variables That Affect Timeline:
- Simple services: Can compress to 3-4 weeks
- Complex, data-critical systems: May require 12+ weeks
- Systems with strict compliance requirements: Add 2-4 weeks for audit and validation
- Microservices architectures: Can be done service-by-service, but total program may span months
How Do You Handle Database Migrations and State Changes?
Read-Only Traffic:
Shadowing read-only traffic is straightforward—both systems read from the same data source and you compare outputs.
Write Operations:
Managing state changes (writes) requires a methodical approach. There are several patterns:
-
Dual Writes and Reconciliation: Application writes to both old and new databases. A separate reconciliation job runs continuously to compare data and flag discrepancies in real-time. This is the most common approach.
-
Log-Only Writes: New service executes write operation against its own database, but the result is logged rather than committed. The outcome is compared against output from old system. This avoids data corruption risk but doesn’t test the new database under true write load.
-
Event Sourcing: Both old and new systems consume the same stream of events and process them independently. This provides strong decoupling but requires prior architectural investment in event sourcing patterns.
Recommended Approach:
Dark launch the read paths first. Only after achieving confidence in the new system’s read performance and data consistency should you address the riskier write paths.
For detailed patterns, see our guide on best practices for data migration.
Should We Build Dark Launching Capability In-House or Use a Vendor?
The build-vs-buy decision depends on team expertise and project timelines.
Building In-House:
Provides maximum control and customization. If your team has expertise with service mesh tools like Istio or Linkerd, or reverse proxies like NGINX and Envoy, this is a viable option. However, it can add 2-4 months to project timeline.
Vendor Solutions:
Platforms like LaunchDarkly or ConfigCat offer pre-built feature flagging, traffic management, and dashboards. These can reduce timeline by 6-10 weeks.
Cost Comparison:
- In-house build: $80K-200K in engineering time (upfront)
- Vendor solution: $5K-50K+ annually (ongoing)
Recommendation:
For first-time dark launch implementations or tight timelines, starting with a vendor solution often provides better ROI. Once you’ve validated the approach, you can evaluate building custom tooling if needed.
About This Guide
This guide is based on insights from 40+ enterprise dark launch implementations analyzed by Modernization Intel between 2022-2025, combined with documented best practices from leading technology firms. Our methodology includes:
- Technical review by Principal Architects with 15+ years experience
- Validation against 200+ implementation partner case studies
- Continuous updates based on latest deployment technology
Contributors: Senior Migration Architects, Modernization Intel Research Team Last Updated: January 2026 Next Review: April 2026
Making the right architectural decisions is critical for successful modernization. Modernization Intel provides the unbiased market intelligence you need—from real-world cost data to implementation partner failure rates—to ensure your project doesn’t become a statistic. Get Your Vendor Shortlist.