
Your Multi-Cloud Modernization Strategy Is Flawed
Over 92% of large enterprises now operate in multi-cloud environments, according to a 2024 Gartner figure cited in industry analysis, and 89% of enterprises have adopted multi-cloud strategies while 73% also use hybrid cloud setups according to Flexera data cited in the same analysis (multi-cloud adoption figures). That sounds like consensus.
It isn’t success.
The harder truth is that adoption has become a default posture while execution remains weak. CTOs inherit a mandate to reduce concentration risk, support regional compliance, modernize legacy workloads, and keep platform teams from hard-locking into one provider. Then the program starts with provider selection instead of engineering constraints. That’s where the strategy breaks.
A serious multi-cloud modernization strategy isn’t a sourcing exercise. It’s a workload placement discipline, an abstraction program, and an operating model decision. If those three pieces aren’t designed together, multi-cloud turns into duplicated tooling, fragmented identity, policy drift, and a more expensive form of lock-in.
Multi-Cloud Is Now Standard but Not Successful
More than nine out of ten large enterprises now run in multi-cloud environments, yet that adoption rate overstates actual execution maturity. In many portfolios, multi-cloud is the residue of local decisions made over time, not the result of a coherent modernization design.
A common pattern looks like this. One division standardizes on AWS for data services. Another stays close to Azure because identity, desktop, and licensing already sit inside the Microsoft stack. A third chooses Google Cloud for selected ML workloads. The enterprise later describes the combined estate as strategy, even though the environments were never built to share controls, deployment standards, or portability assumptions.
That distinction matters because cost, resilience, and negotiating power come from operating discipline, not from vendor count alone.
Adoption is real. Operating maturity is uneven.
Earlier adoption figures establish that multi-cloud is now common in large enterprises. What they do not show is whether those estates can move workloads between providers without refactoring, enforce the same policy model across environments, or produce a single view of cost, identity, and service health. Those are the conditions that determine whether multi-cloud creates options or just multiplies overhead.
The sequencing problem is usually visible early. Teams choose a destination cloud first, then ask how to standardize security, observability, and deployment after migration has started. By then, the architecture has often absorbed provider-specific databases, IAM patterns, CI/CD integrations, and logging tools that make later portability expensive.
Multi-cloud usually fails at the operating model layer before it fails at the infrastructure layer.
An estate can span three clouds and still behave like three separate platforms.
The hidden cost sits in duplicated platform work. Every additional provider introduces another identity boundary, another policy syntax, another set of network controls, another incident workflow, and another billing model for FinOps to normalize. This is why firms that skip early workload classification and migration pattern selection for each application domain often end up with slower delivery rather than more flexibility.
The strategic error is treating multi-cloud as the goal
Vendor messaging usually emphasizes resilience and commercial flexibility. Those outcomes are possible. They are also conditional. If failover is untested, data replication is inconsistent, or core services depend on provider-native APIs in the application path, the second cloud functions more as an extra operating burden than as a credible recovery or negotiation option.
For CTOs, three implications follow:
- Treat multi-cloud as a constraint response, not a maturity badge. It makes sense when regulatory separation, regional requirements, acquisition history, or concentration risk justify the added operating load.
- Approve it workload by workload. Portfolio-wide mandates hide major differences in latency tolerance, data gravity, refactoring cost, and recovery requirements.
- Measure success by transferability and control consistency. A multi-cloud estate is only strategic if teams can move, govern, and observe priority workloads without rebuilding the platform each time.
The useful question is not whether the enterprise is already multi-cloud. Many are.
The useful question is whether the workloads that matter can justify the extra complexity, and whether the prerequisites for running them across providers exist.
The Multi-Cloud Decision Framework
Before approving migration funding, force a harder decision than “best cloud for this application.” Decide whether the workload belongs in a single-cloud, hybrid-cloud, or multi-cloud operating model. Those are not interchangeable modernization patterns. They imply different cost structures, staffing demands, and control requirements.
Multi-cloud can deliver redundancy and rapid workload shifting, but it also requires unified management platforms. The often-cited 20-40% infrastructure cost reduction and 50-80% deployment frequency improvement only materialize when governance, FinOps, and SecOps are established at the same time as the architecture, not later (multi-cloud trade-offs and required governance).
Cloud Strategy Decision Matrix
| Criterion | Single-Cloud | Hybrid-Cloud | Multi-Cloud |
|---|---|---|---|
| Operational complexity | Lowest. One provider control plane and fewer cross-platform skills. | Moderate. You manage public cloud plus on-prem integration. | Highest. Multiple provider models, policies, and tooling stacks. |
| Resilience posture | Strong within one provider, weaker against provider-wide concentration risk. | Strong for workloads that need on-prem continuity and cloud burst capacity. | Strongest if failover is engineered and tested across providers. |
| Vendor lock-in risk | Highest if proprietary services sit in core application paths. | Moderate. On-prem or private environments can retain leverage. | Lowest only when workloads are portable and service dependencies are abstracted. |
| Governance burden | Centralized and simpler to standardize. | Broader because cloud and on-prem controls must align. | Broadest because identity, security, observability, and spend controls must span all providers. |
| Regulatory fit | Good when one provider satisfies residency and control needs. | Often strongest for workloads that must keep some assets outside public cloud. | Strong when regulations, regional presence, or product requirements differ by domain. |
| Cost optimization path | Easier to negotiate and operate, but less leverage if one provider pricing dominates. | Can optimize by keeping selected systems in place while modernizing others. | Best potential for placement arbitrage, but only if governance and portability are already in place. |
A lot of teams jump to multi-cloud because they want future flexibility. That logic fails when the application is tightly bound to provider-native services. Portability isn’t a future option if it isn’t designed now.
A board-level scoring model
Use this five-part checklist before classifying any workload:
-
Resilience requirement
If the business case depends on surviving a provider-specific outage, document the failover path and the team that will execute it. -
Compliance boundary
If data or control requirements differ by region or business unit, verify whether hybrid placement solves the problem with less complexity. -
Service dependency depth
If the application relies heavily on provider-native databases, AI services, or event systems, assume multi-cloud friction until the code proves otherwise. -
Operating model readiness
If there is no common FinOps, SecOps, and observability baseline, the projected efficiency gains are theoretical. -
Migration pattern fit
If the modernization path is still unclear, map the workload first using practical migration patterns for software modernization. Strategy follows the migration path, not the other way around.
Practical rule: Choose the simplest cloud model that satisfies resilience, compliance, and performance requirements. Complexity is not a hedge. It’s a cost center unless the workload earns it.
The Non-Negotiable Prerequisite Workload Portability
Most failed multi-cloud programs share one flaw. They distribute workloads without making them movable.
That produces the worst possible outcome: multiple cloud estates with the same lock-in dynamics you were trying to escape. The application runs in more than one place on paper, but in practice the code, infrastructure definitions, and operational dependencies tie it to one provider.
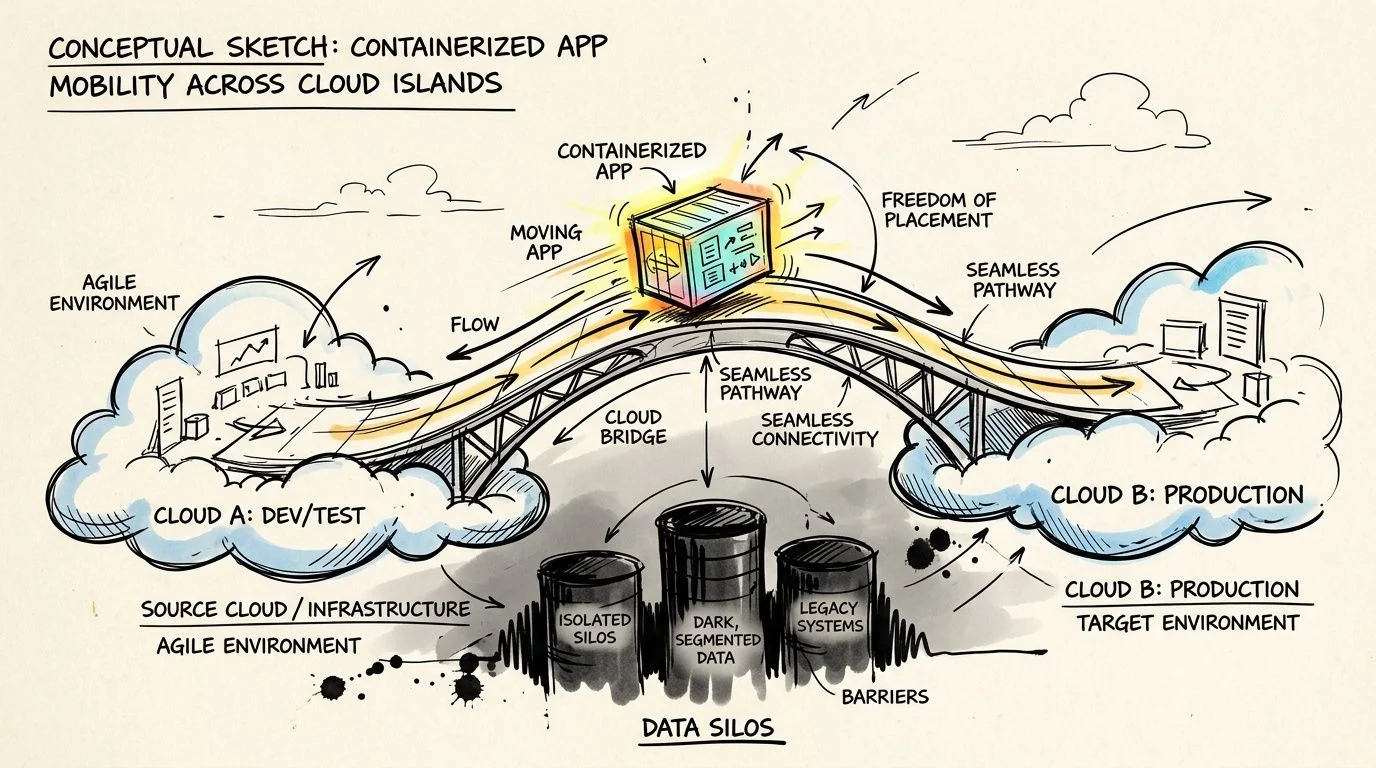
Portability has three engineering pillars
Start with containerization. If you can’t package and run the workload consistently, every migration becomes a rewrite disguised as an infrastructure move. Kubernetes is useful here not because it’s fashionable, but because it gives teams a common orchestration layer across providers.
Then standardize Infrastructure as Code with provider-agnostic tooling such as Terraform. That forces infrastructure decisions into reviewable definitions rather than hand-built provider-specific configurations. Teams looking for implementation detail on this discipline will get more value from this practical resource on modernizing cloud operations with Kogifi than from another generic architecture diagram.
The third pillar is the one most programs avoid because it’s expensive up front. Eliminate provider-specific service assumptions in application code. Hardcoded dependencies on managed messaging, proprietary data services, or AI pipelines destroy mobility even when the surrounding infrastructure looks portable.
The financial case is already proven
This isn’t an academic purity test. A media company moved its recommendation engine from AWS SageMaker to Google Cloud Platform Vertex AI and reduced monthly infrastructure costs by 31%. That move worked because the application had already been abstracted through containerization and cloud-agnostic design (workload portability case with cost reduction).
That example matters because it reframes abstraction as a cost lever, not just an architecture preference.
Portability changes your negotiating position. Without it, cloud pricing is something you absorb. With it, cloud pricing becomes something you can respond to.
What to reject in migration plans
If a modernization partner presents a multi-cloud roadmap without these signals, push back:
- Container plan missing. If there is no explicit packaging and orchestration standard, mobility claims are empty.
- IaC tied to one provider. If infrastructure definitions mirror one provider’s service model too closely, portability will degrade over time.
- Code dependency audit absent. If nobody has mapped proprietary SDKs, data services, and identity assumptions, the lock-in is already embedded.
- No portability acceptance test. If the team can’t define what “movable workload” means in operational terms, the program will drift into platform sprawl.
A credible multi-cloud modernization strategy starts by making workloads portable enough to leave.
Failure Analysis Why Multi-Cloud Strategies Collapse
The headline risk isn’t complexity in the abstract. It’s specific technical failures that keep showing up in replatforming work.
Our analysis found a 67% failure rate for multi-cloud replatforming projects, with major causes including inconsistent data serialization, which affects 40% of financial workloads, and poor workload-to-provider mapping, which drives 25% cost overruns. For legacy-heavy paths, COBOL-to-multi-cloud modernization costs range from $2.50 to $5.50 per line of code (failure rates and cost ranges in multi-cloud replatforming).
Failure mode one is data behavior, not infrastructure
Legacy modernization teams still underestimate what happens when data formats cross platform boundaries. Financial systems are especially exposed because precision loss is not a cosmetic bug. Inconsistent serialization can corrupt calculations, break reconciliation, and create downstream audit problems long before anyone notices at the infrastructure layer.
This is why “successful migration” can’t mean that servers came up and services passed smoke tests. It has to include workload-specific data validation under production-like conditions.
Failure mode two is bad placement logic
Poor workload-to-provider mapping is a strategic error disguised as architecture. Teams choose a provider because of enterprise agreements, internal familiarity, or broad claims about AI capabilities, then force-fit workloads that don’t belong there.
That decision shows up later as overruns, unstable performance, or expensive redesign. The mistake wasn’t migration execution. The mistake was selecting the wrong target model for the workload.
Use a formal cloud migration risk assessment before you classify a legacy estate as a multi-cloud candidate. It will surface whether the fundamental problem is architecture, code quality, dependency sprawl, or operational readiness.
A workload that cannot tolerate data fidelity issues is not a candidate for aggressive multi-cloud replatforming until those issues are isolated and tested.
When not to pursue multi-cloud
This is the decision most guides avoid because it kills momentum. Sometimes multi-cloud is the wrong near-term move.
If technical debt already dominates the codebase, adding provider diversity often multiplies remediation work instead of reducing risk. In those cases, a narrower modernization path usually creates a better business outcome: stabilize, isolate dependencies, move to one cloud where appropriate, and earn portability later.
Red flags that should slow or stop a multi-cloud push:
- Legacy financial logic with known serialization sensitivity
- Deep provider-specific code in core transaction paths
- Security and identity controls that differ by business unit
- No tested failover runbooks across platforms
- RFP responses that promise “end-to-end transformation” without naming workload-specific risks
The contrarian position is usually the correct one here. A weaker scope with stronger execution beats a broad multi-cloud mandate that no team can operate.
Matching Modernization Partners to Migration Paths
Most partner selection fails before the first workshop. The RFP asks for generic cloud modernization capability, broad industry coverage, and enterprise scale. That filters for sales maturity, not delivery fit.
The right question is narrower: which migration path are you buying, and what kind of evidence proves the partner can execute that path in your context?
General capability is not specialization
A partner that handles banking resilience is not interchangeable with a partner that excels in telecom edge integration. The domain matters because migration risk lives in the details: transaction integrity, latency tolerance, regulatory boundaries, integration surfaces, and rollback complexity.
For a CTO, the evaluation unit should be the migration path, not the vendor brand. Examples include:
| Migration path | What partner evidence should look like |
|---|---|
| Mainframe or COBOL replatforming | Experience handling data fidelity issues, transaction semantics, batch orchestration, and regulated workloads |
| Containerization for portability | Clear abstraction standards, Kubernetes operating model experience, and evidence that provider-specific dependencies were removed |
| Data platform migration | Proven control over schema evolution, data movement validation, lineage, and platform cutover planning |
| Edge or latency-sensitive modernization | Experience with distributed deployment patterns, network interconnect design, and operational visibility across locations |
| Security infrastructure migration | Cross-cloud identity, policy standardization, secrets handling, and incident response alignment |
Questions that expose real fit
You don’t need a long scorecard. You need the right pressure tests.
Ask these in live diligence sessions:
- Show the hardest workload you migrated on this path. Not the prettiest one. The hardest one.
- Which provider-specific services did you remove or retain, and why?
- Where did the project stall, and what did you change in the plan?
- What acceptance tests proved portability, data integrity, or failover readiness?
- Which team owned post-migration governance after cutover?
A weak partner answers with framework language. A strong partner answers with constraints, trade-offs, and scars.
Match the operating model too
A partner can be technically competent and still be wrong for your environment. If your internal team is thin, the partner has to leave behind runnable standards and governance artifacts, not just migrated workloads. If your platform team is strong, you may want a specialist that solves the hard engineering problem and exits.
Buy proven depth on the exact migration path you need. Don’t buy broad confidence and hope it converts into specialization later.
The partner decision is not procurement hygiene. It’s architecture risk management.
An Actionable Roadmap for Defensible Multi-Cloud
A defensible multi-cloud modernization strategy has four stages. Skip one, and the costs surface later as rework, shadow spend, or operational drag.
Start with the roadmap, not the provider workshop.
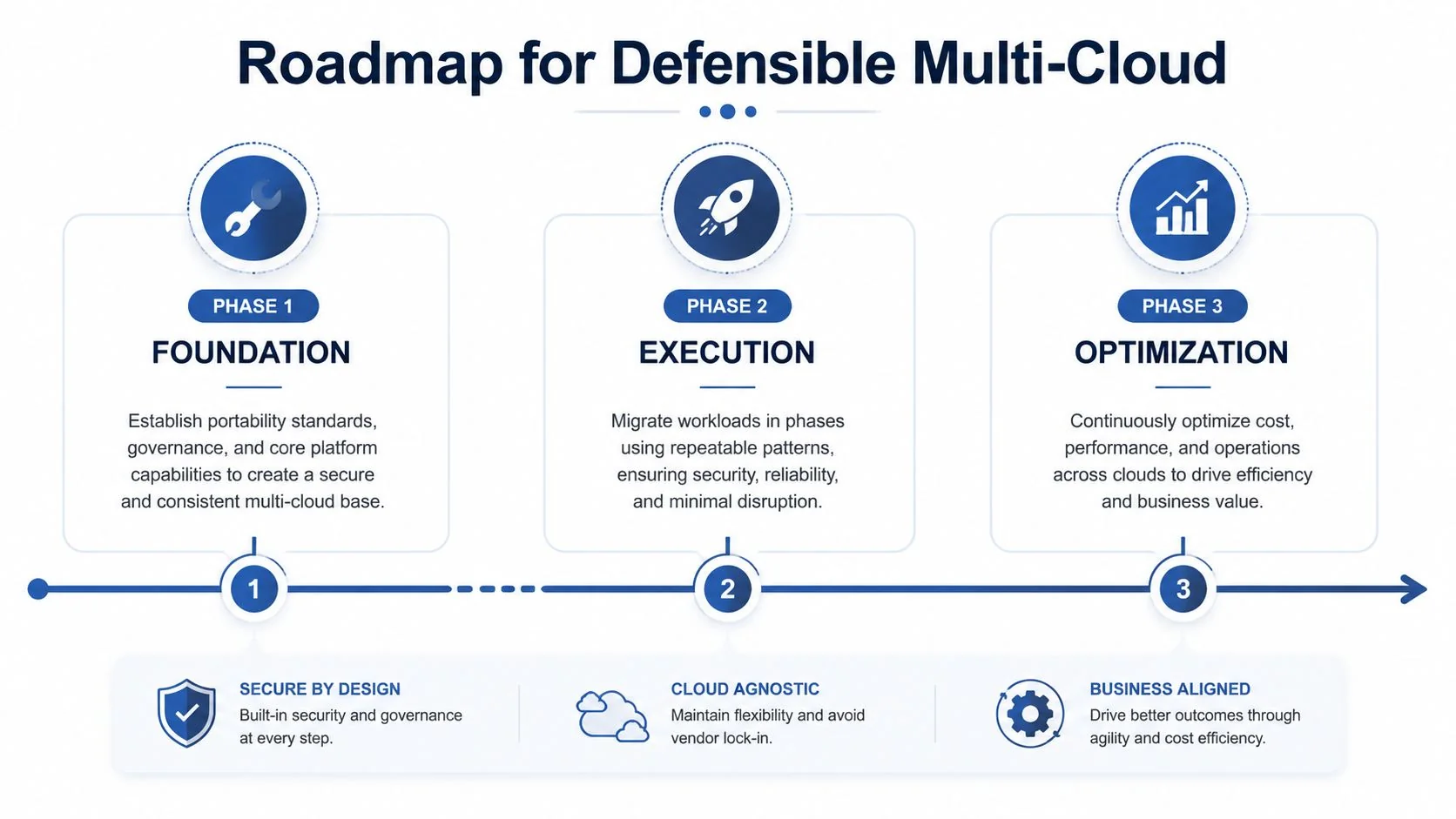
Assess and abstract
Assess the portfolio first. Inventory workloads, map dependencies, classify regulatory constraints, and decide which systems require multi-cloud characteristics. Don’t approve broad replatforming on the basis of estate sprawl alone.
Abstract before moving. Containerize where it makes sense, standardize Infrastructure as Code, and isolate provider-specific dependencies. This is also the point to define architecture guardrails for identity, logging, encryption, and network policy.
For leaders working through control alignment across mixed environments, this hybrid cloud security guide is a useful companion because it focuses on how security standards hold together across architectures, not just within one cloud.
Migrate in phases, then govern aggressively
Pilot first with workloads that are important enough to matter and contained enough to reverse. Measure deployment friction, rollback quality, cost visibility, and operational handoff. Then expand only when the pilot proves the operating model works.
The long-tail cost sits in governance. Emerging trends projected for 2026 show 35% latency reduction via distributed edge gateways across AWS, Azure, and Google Cloud, but 60% of these projects fail without neutral interconnects like Equinix Fabric. The same analysis says only 22% of enterprises implement observability from day one, leading to 40% undetected shadow spend in multi-cloud environments (projected edge and observability risks in multi-cloud).
That projection matters now because it changes design priorities. If edge, OT, or distributed workloads are on your roadmap, observability and interconnect design can’t be deferred.
Here’s a concise explanation of the operating challenge:
A four-step execution sequence
-
Assess
Build a workload inventory, dependency map, and strategy classification. Decide where single-cloud or hybrid solves the need with less complexity. -
Abstract
Establish portability standards in code and infrastructure. Refuse provider lock-in in the parts of the estate that require future mobility. -
Migrate
Start with a pilot, validate data behavior, test rollback, and measure the operational burden on the platform team. -
Govern
Implement FinOps, SecOps, and observability from day one. Extend those controls to edge and OT-connected workloads before scale makes drift harder to reverse.
The strongest modernization programs don’t try to prove they can run everywhere. They prove they can move, govern, and recover with intent.
Multi-cloud isn’t the goal. A controlled, testable, economically rational operating model is the goal.
If you’re evaluating partners or deciding whether a workload belongs in single-cloud, hybrid, or multi-cloud, Modernization Intel publishes evidence-based research on migration paths, failure risks, cost ranges, and partner specialization at Software Modernization Intelligence.