
What Are Migration Patterns in Cloud Computing
Migration patterns are the strategic blueprints for moving applications from an on-premises data center to a public cloud. But let’s be direct: they are not technical execution plans. Think of them as the high-level decision you make before the real work begins.
Choosing a pattern is a strategic business call that sets the cost, risk, and timeline for the entire migration. Getting this wrong is the number one reason large-scale modernization efforts fail.
Defining Your Cloud Migration Strategy
Picking the wrong migration pattern is a catastrophic, unrecoverable error. It’s the moment you commit to spending millions refactoring an application that should have been retired. Or when you waste years rehosting a monolith that desperately needed a rewrite.
This isn’t a technical misstep that happens mid-project; it’s a fundamental failure of strategy that occurs in the first week, long before a single engineer touches a line of code.
The goal is to match the right approach to the right application by weighing its business value, its technical condition, and the actual goal of the move. For a deeper look at how these patterns fit into the bigger picture, check out our guide on application modernization strategies.
The Spectrum of Migration Patterns
Migration patterns exist on a spectrum, from low-effort with low rewards to high-effort with high rewards. A “lift-and-shift” rehost is fast and cheap, but you get almost none of the real benefits of the cloud. On the flip side, a full refactor into microservices is expensive and slow but can unlock scalability and development velocity.
Choosing a migration pattern isn’t about what’s technically “best”—it’s about what’s strategically sound. A high-cost refactor is a waste of capital if the application isn’t a core revenue driver, just as a quick rehost is a missed opportunity for a system that’s crippling your business.
The key is brutal honesty. That internal HR tool from 1998 doesn’t need to be “cloud-native.” But your customer-facing e-commerce platform that handles 90% of your revenue? It probably does. Misdiagnosing an application’s value leads directly to misaligned investment and failed projects.
The 10 Cloud Migration Patterns (The R’s and Beyond)
The original “5 R’s” from Gartner are a decent starting point, but the 2025 cloud reality is more complex. The modern playbook includes patterns for dealing with monoliths, containers, and massive data gravity. Here’s the full list, from simple moves to complex architectural shifts.
1. Rehost (“Lift-and-Shift”)
Fastest time-to-cloud, lowest risk. Move VMs/databases as-is using AWS Server Migration Service (SMS), Azure Migrate, Google Cloud Migrate for Compute Engine, or VMware HCX. 2025 reality: still the correct first move for 65–75% of workloads when you have hard regulatory or M&A deadlines.
2. Replatform (“Lift-Tinker-and-Shift”)
Minimal code changes for big wins: on-prem Oracle/SQL Server → managed Amazon RDS/Aurora, WebLogic → Tomcat on AWS Fargate, IIS → AWS Elastic Beanstalk. Typical ROI: 30–50% lower ops cost, zero-downtime cutovers with AWS Database Migration Service (DMS) CDC.
3. Repurchase (“Drop-and-Shop”)
Replace with SaaS: Salesforce instead of Siebel, Workday instead of PeopleSoft, ServiceNow instead of Remedy. Highest ROI long-term but highest org-change pain. 2025 rule: only repurchase if the vendor already owns >70% of the roadmap you need.
4. Refactor / Re-architect
Break monoliths into microservices, move to containers (EKS/AKS/GKE) or serverless (Lambda, Cloud Functions). Only justified when you need >10× scale, sub-100 ms latency, or independent team deployment velocity. Costs 3–10× more than rehost; never do it “because cloud-native is cool.” For a deep dive, see our guide on the Strangler Fig Pattern with examples.
5. Retire / Decommission
The highest-ROI pattern nobody budgets for. 15–30% of legacy apps are unused or duplicated. Kill them before migration and save millions in perpetual licensing and cloud spend.
6. Retain / Hybrid
Keep on-prem or in private cloud forever (mainframes, ultra-low latency trading, nuclear SCADA, massive Oracle Exadata that costs less on-prem). 2025 twist: run new workloads in public cloud while keeping the old beast behind AWS Outposts, Azure Stack, or Google Anthos until natural EOL.
7. Relocate
Hypervisor-to-hypervisor moves with zero architecture change (VMware on-prem → VMware Cloud on AWS, VMware → Azure VMware Solution, Hyper-V → GCP Bare Metal). Perfect for companies that want cloud billing but refuse to touch the app.
8. Containerize-First (The 2025 Dark Horse)
New default for any custom web app or backend service: package once into Open Container Initiative (OCI) containers, run anywhere (Amazon EKS Anywhere, Azure AKS, Google GKE, on-prem Kubernetes, Google Cloud Run, Azure Container Apps). Decouples “where it runs” from “how it’s built” and kills future migration tax.
9. Data-Gravity Reverse Migration (The One Nobody Talks About)
When 100+ TB datasets become too expensive to egress or need <5 ms latency, move the compute back closer to the data (Snowball Edge, Outposts, GCP Distributed Cloud, Azure Local). Happens more in 2025 with GenAI training/inference datasets.
10. Strangler-Fig Pattern (The Only Safe Way to Kill a 25-Year Monolith)
Incrementally extract domains to new cloud-native services behind a facade (Amazon API Gateway, Istio, AWS App Mesh). Each release retires another piece of the old system until nothing is left. Takes 18–36 months but is the only proven way to refactor without a Big Bang death march.
High-Effort, High-Reward Patterns: Refactor and Rearchitect
While the easier patterns get you quick wins, Refactor and Rearchitect are the heavy hitters. This is the high-stakes, big-budget end of the migration spectrum, reserved for core business applications where small tweaks just won’t cut it anymore. We’re talking about fundamentally changing an application’s structure to unlock capabilities that are currently impossible.
Both patterns usually mean breaking down a monolith into smaller, independent pieces like microservices or serverless functions. But they are not the same, and the business case for each is critically different. Choosing this path just because “cloud-native is cool” is a surefire way to blow your budget and kill your project. The business case has to be rock-solid.
Distinguishing Refactor from Rearchitect
People throw these terms around interchangeably, but their drivers are worlds apart. Nailing this difference is the key to justifying the massive investment.
- Refactor: This is about changing the internal structure of the code without changing its external behavior. The goal is to improve things like performance, maintainability, or scalability. You might refactor a critical service to hit a sub-100 ms latency target because the current lag is costing you customers.
- Rearchitect: This is a much deeper change to the application’s fundamental architecture. The driver here is usually organizational or strategic. You might rearchitect a monolith to enable independent team deployment velocity, letting different product teams ship features on their own schedule without a massive, coordinated release day.
Simply put: you refactor to make the current application better. You rearchitect to change how your organization builds and ships that application.
The decision to refactor or rearchitect is never just technical. It must be directly tied to a business outcome: more revenue from better performance, faster time-to-market from agile teams, or the ability to enter a new global market. Anything less is just an expensive science project.
The Stark Realities of Cost and Risk
Going down this path requires a clear-eyed view of the investment. A full refactor can easily cost 3 to 10 times more than a simple rehost. It’s a multi-year commitment that brings on significant risk if you don’t manage it with extreme discipline. You’re essentially rebuilding the engine of a plane while it’s in the air.
This is why phased, incremental approaches are non-negotiable. For a deep dive into a proven, lower-risk method for safely dismantling a large legacy system, check out our guide on the Strangler Fig Pattern with examples. This strategy lets you systematically carve off and replace pieces of the monolith over time, steering clear of a “big bang” cutover that rarely succeeds.
Ultimately, refactoring is only worth it when the pain of the old architecture is more expensive than the migration itself. When you absolutely need to achieve >10x scale, unlock elite development speed, or meet non-negotiable performance SLAs, refactoring stops being an engineering exercise and becomes a necessary strategic investment.
The CTOs Decision Matrix for Choosing the Right Pattern
Knowing the different migration patterns is one thing. Knowing which one to use for which application is the real game. This is the single most critical decision a CTO makes during a modernization effort, and getting it wrong has compounding financial and operational consequences.
Pick the wrong pattern, and you’ll either waste millions refactoring an app that just needed a simple lift-and-shift, or you’ll waste years rehosting a legacy system that should have been retired. The analysis isn’t rocket science, but it does demand brutal honesty about an application’s actual business value versus its perceived importance.
This framework is your first line of defense against a catastrophic strategic error.
Matching Patterns to Business Reality
Every pattern is a trade-off. Rehost is fast and cheap but delivers almost zero cloud-native value. Refactor is slow and expensive but can fundamentally reshape your business capabilities. There is no “best” pattern, only the one that best serves a specific, measurable business goal.
The most common failure we see is treating all applications the same. Your high-volume e-commerce platform and the internal HR tool from 2005 do not deserve the same investment or risk profile. Forcing a one-size-fits-all strategy across a diverse portfolio is a surefire way to blow your budget and stall the entire program.
This decision flow gives you a simplified mental model for modern workloads. It guides you from custom applications toward containerization and from old monoliths toward smarter strategies like the Strangler Fig pattern.
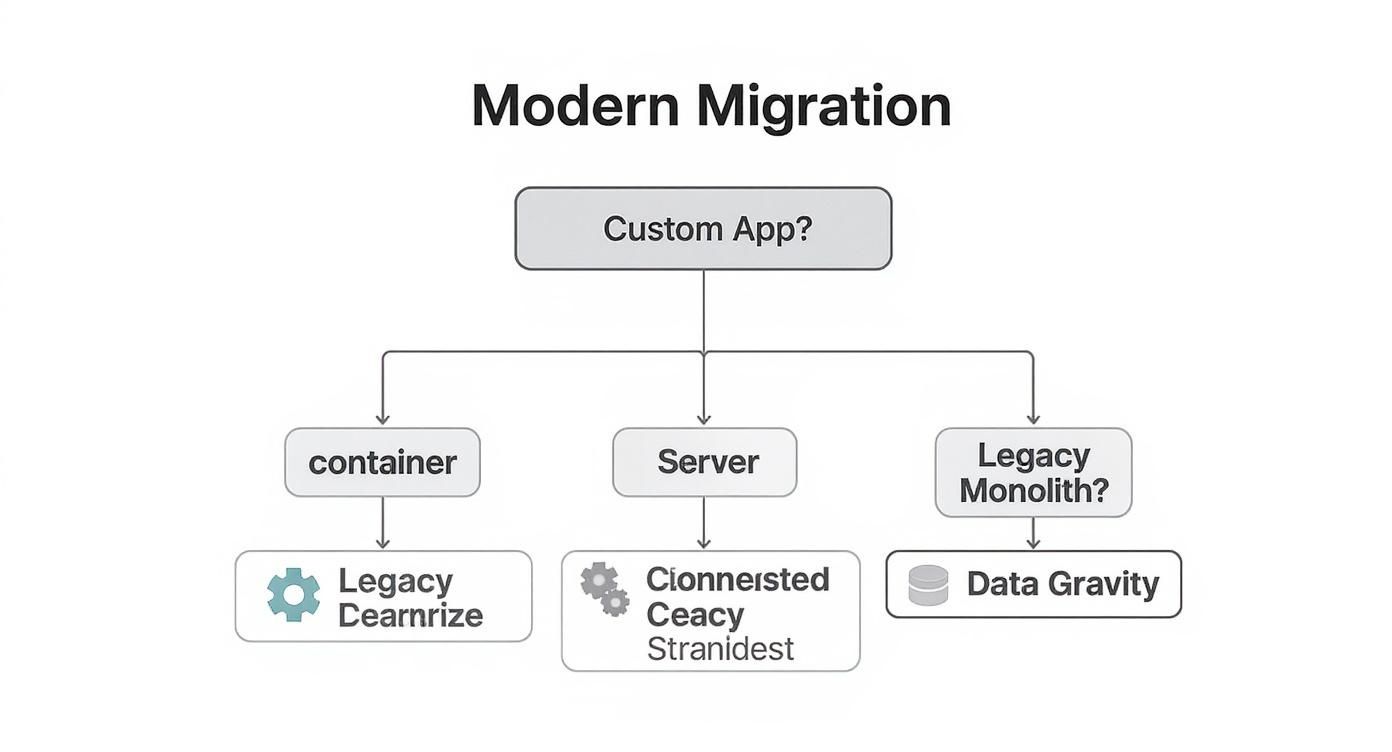
The key takeaway? Modern patterns are highly specialized. The right choice depends entirely on the application’s architecture and the business problem you’re trying to solve.
Decision Matrix Every CTO Should Use
| Pattern | Time to Value | Cost | Risk | When It’s Right |
|---|---|---|---|---|
| Rehost | 1–3 months | $ | Low | Deadlines, M&A |
| Replatform | 3–6 months | $$ | Low | Managed DB win |
| Refactor | 12–36 months | $$$$ | High | Velocity/scale need |
| Repurchase | 6–18 months | $$$ | Med | Feature parity exists |
| Retire | Immediate | –$$ | Low | Anything unused |
| Strangler | 18–36 months | $$$ | Med | Monolith death |
Pick the wrong pattern and you’ll either waste millions refactoring something that should have been rehosted, or waste years rehosting something that should have been retired. Use the matrix once, brutally, in week one — your future self will thank you.
Straight Answers to Hard Questions
Knowing the textbook definitions of migration patterns is one thing. Applying them in the real world—where budgets are tight and legacy code is a mess—is another game entirely. Technical leaders hit the same walls and ask the same tough questions.
Here are the direct answers, based on what we’ve seen work (and fail spectacularly) in the field. This isn’t theory; this is the reality you face when a migration plan meets your actual systems.
Replatform vs. Refactor: When Do You Choose Which?
This decision has nothing to do with technology and everything to do with the business driver. The real question is: are you chasing an efficiency gain or a fundamental business model change?
Go with Replatform for a quick win with a fast ROI. It’s the classic 80/20 move—you get roughly 80% of the benefit for 20% of the effort. A perfect example is moving an on-premise database to a managed cloud service like Amazon RDS. You immediately kill licensing fees and operational headaches. It’s a smart, tactical play.
Only choose Refactor when your application’s architecture is a direct bottleneck to making money or keeping up with competitors. If your system physically cannot scale to meet customer demand, or if your painfully slow deployment speed means you can’t ship features fast enough, then a refactor is justified. Otherwise, it’s just an expensive science project that burns cash for no clear return.
Picking Refactor without a rock-solid business case is the single most common multi-million dollar mistake we see companies make. It has to be driven by a non-negotiable need for massive scale or development velocity—not just a vague desire to be “cloud-native.”
Is the Strangler-Fig Pattern Always the Best Way to Kill a Monolith?
It’s the safest way to decommission a complex, high-risk monolith without a “big bang” failure, but it’s definitely not always the best way. This pattern is a serious commitment, demanding 18–36 months of unwavering architectural discipline.
The Strangler-Fig is reserved for systems that are too valuable to turn off but far too risky to rewrite in one go. If a monolith is non-critical, has low business impact, or could be replaced entirely by a SaaS tool (Repurchase), those are much faster and cheaper options. Don’t bring a scalpel when a sledgehammer will do the job.
When Does It Actually Make Sense to Just Rehost?
Rehosting often gets a bad rap as a lazy “lift-and-shift,” but it’s the right strategic call in a few specific scenarios where speed is everything and risk has to be minimized.
- Hard Deadlines: You have to be out of a data center before a contract expires. An M&A deal requires you to integrate systems by a fixed date. There’s simply no time for anything fancier.
- Stable, “Don’t Touch It” Apps: The application works, it’s not under active development, and there’s no business reason to change it. Rehosting is a perfectly logical move here.
- Portfolio-Wide Lift: This is a tactical first step to get an entire application portfolio into the cloud quickly, stop the on-prem spending bleed, and then circle back to optimize high-value applications later.
In these cases, a lift-and-shift isn’t a technical shortcut. It’s a sound business decision that prioritizes the most urgent needs over long-term perfection.
Choosing the right migration pattern is just step one. Picking the right implementation partner is where most of these projects actually succeed or fail. Modernization Intel gives you the unvarnished truth on 200+ partners, their real costs, and their hidden failure rates, so you can make a defensible decision without the vendor sales pitch. Get your vendor shortlist at https://softwaremodernizationservices.com.